












PGI CUDA Fortran Compiler
Unidades de processamento de gráficos ou GPUs evoluíram em unidades computacionais programáveis e altamente paralelas com largura de banda de memória muito alta. Os designs de GPU são otimizados para as computações encontradas na renderização de elementos gráficos, mas são gerais o suficiente para serem úteis em muitos programas de computação intensiva em paralelo de dados, comuns em computação de alto desempenho (HPC).
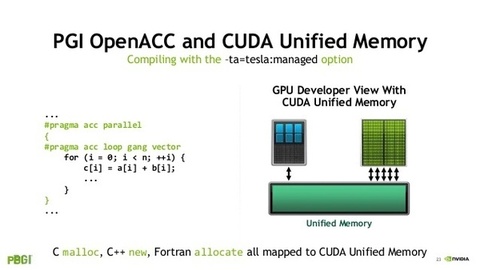
O CUBA é uma plataforma de computação paralela e um modelo de programação para unidades de processamento gráfico (GPUs). O ambiente de programação original do CDA foi constituído por um compilador C estendido e uma cadeia de ferramentas, conhecida como a Cuda C. Cuda C permitiu a programação direta da GPU a partir de uma linguagem de alto nível.
Fabricante: NVIDIA Corporation
Descrição detalhada do produto

SOLICITE SEU ORÇAMENTO
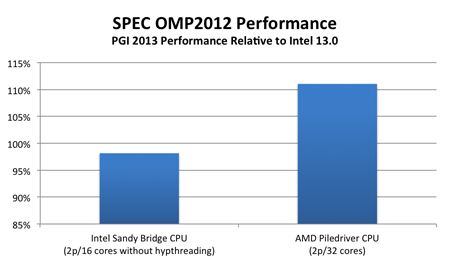
O CUDA suporta quatro abstrações principais: threads cooperativos organizados em grupos de threads, sincronização de memória e barreira compartilhada dentro de grupos de threads e grupos de threads independentes coordenados organizados em uma grade. Um programador da cúpula é necessário para particionar o programa em blocos de grãos grosseiros que podem ser executados em paralelo. Cada bloco é particionado em segmentos de grão fino, que podem cooperar usando memória compartilhada e sincronização de barreira. Um programa de uma forma adequada será executado em qualquer GPU habilitada para a cúpula, independentemente do número de núcleos de processador disponíveis
Quando chamado a partir do programa host Fortran, as sub-rotinas definidas pelo Fortran da CUDA são executadas em paralelo na GPU. Chamadas para tais sub-rotinas — também conhecidas como kernels — especificam quantas instâncias paralelas do kernel executar. Cada instância é executada por um thread do cubo. Os threads da cúpula são organizados em blocos de threads. Cada thread tem um índice de bloco de thread global e um índice de thread local dentro de seu bloco de thread.
Obrigado! Logo entraremos em contato!
Baixe o Guia Software.com.br 2024



































